15.1 Podpora hardvéru a softvéru pre AI
Novšie modely procesora Raspberry Pi obsahujú viacero ARM jadier. Napriek slušným hardvérovým schopnostiam môže Raspberry Pi zápasiť s výpočtovými nárokmi náročnejších aplikácií umelej inteligencie (AI). Pre náročnejšie aplikácie existuje doplnková doska Raspberry Pi — nazývaná HAT (Hardware Attached on Top), ktorá poskytuje NPU (Neural Processing Unit) na zrýchlenie výpočtov strojového učenia. Raspberry Pi AI HAT+ poskytuje vysoko výkonný, energeticky efektívny AI procesor pre Raspberry Pi 5. Okrem hardvérovej podpory existuje široká škála výkonných knižníc strojového učenia, ktoré je možné používať s Raspberry Pi, vrátane scikitlearn a LiteRT. Python obsahuje množstvo výkonných podporných knižníc, ako sú Matplotlib a plotly na kreslenie, NumPy na rýchle operácie s poliami a Pandas na analýzu a manipuláciu s dátami. Nasledujúce časti uvádzajú príklady niektorých z týchto knižníc v praxi.
15.2 SciKit Learn
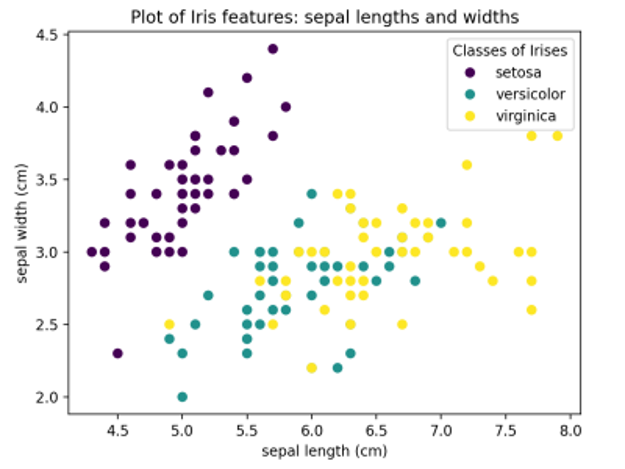
SciKit Learn je open source knižnica strojového učenia, ktorá pracuje s Pythonom. SciKit Learn poskytuje mnoho rôznych funkcií, vrátane regresných a klastrovacích algoritmov, analýzy hlavných komponentov (PCA), lineárnej diskriminačnej analýzy (LDA) a podporných vektorových strojov (SVM). Všetky formy strojového učenia vyžadujú dátovú sadu, ktorá sa používa na tréning. SciKit obsahuje výber hračkárskych dátových súborov, ktoré možno použiť na experimentovanie s knižnicami strojového učenia. Nasledujúce časti demonštrujú PCA a SVM pomocou klasického datasetu kvetov kosatcov, ktorý je súčasťou zbierky dátových súborov hračiek. Tento súbor dúhoviek pôvodne zostavil biológ Ronald Fisher v známom článku z roku 1936. Táto databáza obsahuje vzorky troch druhov kvetu kosatcov (Iris setosa, Iris virginica a Iris versicolor) a merania dĺžky a šírky kališných lístkov1 aj lupienkov. Knižnica SciKit Learn obsahuje tento súbor dúhoviek na testovanie a demonštračné účely. Nasledujúci Python kód používa Matplotlib na vykreslenie šírky kališného lístka v porovnaní s dĺžkou kališného lístka pre každú z troch tried iris v datasete.
z sklearn import datasetov
importovať matplotlib.Pyplot ako PLT
# Načítaj klasickú sadu dát o dúhovke
Iris = dátové súbory.load_iris()
# Vykresliť dĺžky kališných lístkov vs. šírky pre dúhovky v datasete
Obr., Ax = Plt.vedľajšie dejové línie()
scatter = os.scatter(Iris.Data[:, 0], Iris.dáta[:, 1], c=iris.cieľ)
Ax.set_title("Rysy rysov kosatcov: dĺžky a šírky kališných lístkov")
Ax.set(xlabel=iris.feature_names[0], ylabel=iris.feature_names[1])
obr. = sekera.legenda (scatter.legend_elements()[0], iris.target_names, loc="najlepšie
", názov = "Triedy kosatcov")
Plt.show()
Spustenie tohto kódu vedie k nasledujúcemu grafu dátovej sady iris:
15.3 Klasifikácia SVM obrázkov
Nasledujúci príklad je inšpirovaný príkladom SciKit o rozpoznávaní ručne písaných číslic a využíva dataset ručne písaných číslic z repozitára strojového učenia UC Irvine. Táto datasada obsahuje 1797 vzoriek obrázkov zložených zpoľa 8 x 8 pixelov s 10 triedami, kde každá trieda odkazuje na jednu číslicu (09). Krátky program v Pythone na načítanie ručne písaných číslic a ich zobrazenie je zobrazený nižšie:
importovať matplotlib.Pyplot ako PLT
zo SKLEARN importujte datasety, metriky, svm
od sklearn.model_selection import train_test_split
# načítať ručne písané číslice dátovej sady
Číslice = dátové súbory.load_digits()
# zobrazuje vzorku desiatich ručne písaných číslic v datasete
Obr., Axes = Plt.vedľajšie dejové línie (nrows=2, ncols=5)
Pre sekeru, číslica v zip (axes.flatten(), digits.obrázky):
Ax.set_axis_off()
Ax.imshow(digit,cmap='šedá')
Fig.tight_layout()
Plt.show()
Graf zobrazujúci desať ručne písaných číslic v datasete je zobrazený nižšie.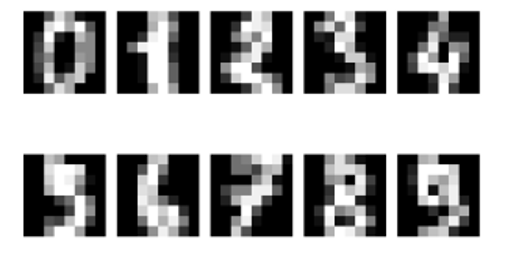
Súbor ručne písaných číslic môžeme rozdeliť na dve sady: tréningovú sadu a sadu na testovanie. SciKit má funkciu na rozdelenie väčšej množiny číslic na dve polovice na tréningové a testovacie množiny nasledovne:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0,5)
kde X je pole znakov a y je vektor štítkov, ktoré klasifikujú dáta. Preto môžeme pokračovať v trénovaní SVM s polovicou datasetu na trénovanie a zvyšnú polovicu datasetu použiť na testovanie. Presnosť SVM je možné určiť porovnaním číslic predpovedaných SVM s reálnymi štítkami pre ručne písané číslice a možno hlásiť mieru rozpoznania. Miera rozpoznávania je celkový počet správne identifikovaných obrázkov číslic delený celkovým počtom testovacích snímok. Nasledujúci kód definuje SVM klasifikátor na základe polovice datasetu a následne určuje rýchlosť rozpoznávania pomocou druhej polovice datasetu ako testovacích obrázkov.
importovať matplotlib.Pyplot ako PLT
zo SKLEARN importujte datasety, metriky, svm
od sklearn.model_selection import train_test_split
# Čítaj číslice a pretvaruj ich ako vektor obrázkov
Číslice = dátové súbory.load_digits()
n_samples = len(číslice.obrázky)
dáta = číslice.obrázky.reshape((n_samples, -1))
# Vytvoriť podporný vektorový strojový klasifikátor
svm = svm.SVC()
# Rozdeľte dátovú sadu: polovicu na trénovanie a polovicu na testovanie
X_train, X_test, y_train, y_test = train_test_split(
Dáta, číslice.cieľ, test_size=0,5, zamiešanie=Nepravda)
# Trénuj na ručne písaných čísliciach v tréningovej sade
SVM.fit(X_train, y_train)
# Predpovedajte hodnotu číslice pomocou testovacej množiny
Predpovedané = SVM.predpovedať(X_test)
# vypočítaj mieru rozpoznávania
Zápasy = 0
pre x v rozsahu(len(y_test)):
ak y_test[x] == predpovedané[x]:
Zápasy += 1
recognition_rate = (zhody/len(y_test)) * 100;
print(f'Recognition rate: {recognition_rate:.2f}%')
Výstup tohto kódu ukazuje nasledovné:
Miera rozpoznateľnosti: 96,11 %
To naznačuje slušnú mieru rozpoznania pri použití SVM na klasifikáciu ručne písaných číslic. Pre viac detailov môžeme vykresliť maticu zmätku na vizualizáciu presnosti algoritmu strojového učenia. Matica zmätku je organizovaná do riadkov a stĺpcov: každý riadok predstavuje jednotlivé triedy v datasete a každý stĺpec predstavuje vykonané predpovede. Ideálne by sa skutočné triedy a predpovede dokonale zosúladili tak, že diagonála matice zmätku bude vyplnená stovkami a všade inde nulami. Diagonálny martix zodpovedá skutočným mieram rozpoznávania, zatiaľ čo všetky ostatné bunky predstavujú výskyt falošných klasifikácií.
Last modified: Friday, 19 June 2026, 6:31 AM