15.1 Hardverska i softverska podrška za AI
Nedavni modeli Raspberri Pi procesora uključuju više ARM jezgara. Uprkos svojim respektabilnim hardverskim mogućnostima, Raspberri Pi može da se bori sa računarskim zahtevima zahtevnijih veštačke inteligencije (AI) aplikacije. Za zahtevnije aplikacije, postoji Raspberri Pi addon ploča - koja se naziva HAT (Hardware Attached on Top) koja obezbeđuje NPU (Neural Processing Unit) za ubrzavanje računara mašinskog učenja. Raspberri Pi AI HAT + obezbeđuje visokoučinkovit, energetski efikasan AI procesor za Raspberri Pi KSNUMKS. Pored hardverske podrške, postoji širok spektar moćnih biblioteka za mašinsko učenje koje se mogu koristiti sa Raspberri Pi, uključujući scikitlearn i LiteRT. Pithon uključuje brojne moćne biblioteke za podršku, kao što su Matplotlib i plotli za crtanje, NumPi za obezbeđivanje brzih operacija na nizovima i Pandas za analizu i manipulaciju podataka. Sledeći odeljci daju primere nekih od ovih biblioteka u akciji.
15.2 SciKit Saznajte
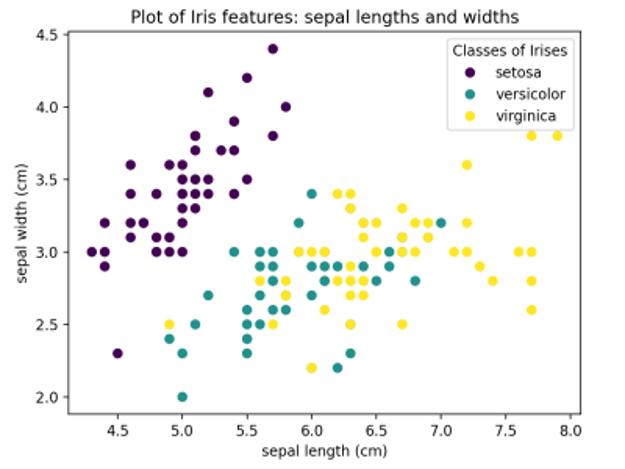
SciKit Learn je biblioteka za mašinsko učenje otvorenog koda koja radi sa Pithonom. SciKit Learn pruža mnogo različitih funkcija, uključujući regresijske i klasterne algoritme, analizu glavnih komponenti (PCA), linearnu diskriminantnu analizu (LDA) i vektorske mašine za podršku (SVM). Svi oblici mašinskog učenja zahtevaju skup podataka koji se koristi za obuku. SciKit uključuje izbor skupova podataka o igračkama koji se mogu koristiti za eksperimentisanje sa bibliotekama mašinskog učenja. Sledeći odeljci pokazuju PCA i SVM koristeći klasični skup podataka o cvetu irisa koji je deo zbirke skupova podataka o igračkama. Ovaj skup podataka irisa je prvobitno sastavio biolog Ronald Fisher u poznatom radu iz 1936. godine. Ovaj skup podataka sadrži uzorke tri vrste cveta Iris (Iris setosa, Iris virginica, i Iris versicolor) i merenja dužine i širine oba sepals1 i latica. Biblioteka SciKit Learn uključuje ovaj skup podataka irisa za potrebe testiranja i demonstracije. Sledeći Pithon kod koristi Matplotlib za crtanje širine čašice u odnosu na dužinu čašice za svaku od tri klase irisa u skupu podataka.
Iz SKLEARN Uvoz skupova podataka
Uvoz matplotlib.Piplot kao PLT
# Učitajte klasični iris skup podataka
Iris = skupovi podataka.load_iris()
# Plot sepal dužine vs. širine za perunike u skupu podataka
fig, ax = plt.podzapleti()
rasipanje = sekira.rasipanje(iris.data[:, 0], iris.data[:, 1], c = iris.meta)
Sekira.set_title("Zemljište Iris karakteristike: sepal dužine i širine")
Sekira.set(xlabel=iris.feature_names[0], ylabel=iris.feature_names[1])
fig = sekira.legenda(rasipanje.legend_elements()[0], iris.target_names, loc="best
", title="Klase perunika")
plt.Šou()
Pokretanje ovog koda rezultira sledećim zemljištem skupa podataka irisa:
15.3 SVM klasifikacija slika
Sledeći primer je inspirisan SciKit primerom o prepoznavanju rukom pisanih cifara i koristi rukom pisane cifre skup podataka iz UC Irvine spremišta mašinskog učenja. Ovaj skup podataka ima 1797 uzoraka slika koji se sastoje od 8k8 niza piksela sa 10 klasa gde se svaka klasa odnosi na jednu cifru (09). Kratak Pithon program za učitavanje rukom pisanih cifara skup podataka i prikaz ih je prikazan ispod:
Uvoz matplotlib.Piplot kao PLT
Od SKLEARN Uvoz skupova podataka, metrika, SVM
iz SKLEARN-a.model_selection uvoz train_test_split
# Učitavanje rukom pisanih cifara skup podataka
cifre = skupovi podataka.load_digits()
# Prikažite uzorak od deset rukom pisanih cifara u skupu podataka
fig, ose = plt.podparcele (nrovs = 2, ncols = 5)
za sekiru, cifra u zip (ose.flatten(), cifre.slike):
Sekira.set_axis_off()
Sekira.imshow(cifra,cmap='siva')
Sl.tight_layout()
plt.Šou()
Zemljište koje prikazuje deset rukom pisanih cifara u skupu podataka prikazano je ispod.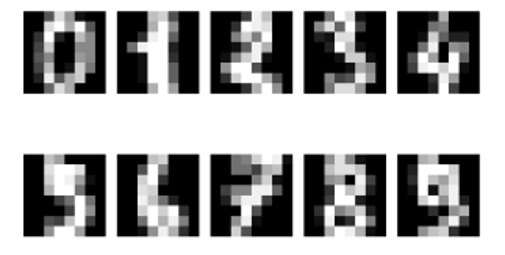
Možemo podeliti rukom pisane cifre skup podataka u dva seta: skup za obuku i skup za testiranje. SciKit ima funkciju za uzimanje većih cifara skupa podataka i razdvajanje na pola u skupove za obuku i testiranje na sledeći način:
X_train, X_test, y_train, y_test = train_test_split (X, y, test_size=0.5)
gde je X niz karakteristika i y je vektor oznaka koje klasifikuju podatke. Stoga možemo nastaviti da treniramo SVM koristeći polovinu skupa podataka za obuku, a zatim koristimo preostalu polovinu skupa podataka za testiranje. Tačnost SVM-a može se odrediti upoređivanjem cifara predviđenih od strane SVM-a sa stvarnim oznakama za rukom pisane cifre i stopa prepoznavanja se može prijaviti. Stopa prepoznavanja je ukupan broj ispravno identifikovanih cifara slika podeljen sa ukupnim brojem test slika. Sledeći kod definiše SVM klasifikator na osnovu polovine skupa podataka, a zatim određuje stopu prepoznavanja koristeći drugu polovinu skupa podataka kao test slike.
Uvoz matplotlib.Piplot kao PLT
Od SKLEARN Uvoz skupova podataka, metrika, SVM
iz SKLEARN-a.model_selection uvoz train_test_split
# Čitajte cifre i preoblikujte cifre kao vektor slika
cifre = skupovi podataka.load_digits()
n_samples = len(cifre.slike)
podaci = cifre.slike.preoblikovati((n_samples, -1))
# Kreirajte vektor podrške mašina klasifikator
svm = svm.SVC()
# Podelite skup podataka: pola za obuku i pola za testiranje
X_train, X_test, y_train, y_test = train_test_split(
podaci, cifre.meta, test_size=0.5, shuffle=False)
# Trenirajte na rukom pisanim ciframa u skupu za obuku
svm.Pipneškom(X_train, y_train)
# Predvidite vrednost cifre pomoću skupa za testiranje
predviđeno = svm.predviđanje(X_test)
# izračunati stopu prepoznavanja
utakmice = 0
za ks u opsegu (len(y_test)):
if y_test[x] == predviđeno [x]:
Utakmice += 1
recognition_rate = (šibice/len(y_test)) * 100;
print(f'Stopa prepoznavanja: {recognition_rate:.2f}%')
Izlaz ovog koda pokazuje sledeće:
Stopa prepoznavanja: 96.11%
Ovo ukazuje na respektabilnu stopu prepoznavanja koristeći SVM za klasifikaciju rukom pisanih cifara. Za više detalja, možemo iscrtati matricu konfuzije kako bismo vizualizovali tačnost algoritma mašinskog učenja. Matrica konfuzije je organizovana u redove i kolone: svaki red predstavlja svaku od klasa u skupu podataka i svaka kolona predstavlja predviđanja koja su napravljena. U idealnom slučaju, stvarne klase i predviđanja će se savršeno uskladiti tako da je dijagonala matrice konfuzije popunjena sa 100 i sa 0 svuda drugde. Dijagonalna martik odgovara pravim stopama prepoznavanja, dok sve ostale ćelije predstavljaju pojave lažnih klasifikacija.
Last modified: Saturday, 20 June 2026, 8:05 AM