15.1 Suporte de Hardware e Software para IA
Modelos recentes do processador Raspberry Pi incluem múltiplos núcleos ARM. Apesar das suas respeitáveis capacidades de hardware, o Raspberry Pi pode ter dificuldades com as exigências computacionais de aplicações de inteligência artificial (IA) mais exigentes. Para aplicações mais exigentes, existe uma placa adicional Raspberry Pi — referida como HAT (Hardware Attached on Top) — que fornece uma NPU (Unidade de Processamento Neural) para acelerar os cálculos de aprendizagem automática. O Raspberry Pi AI HAT+ oferece um processador de IA de alto desempenho e eficiente em termos energéticos para o Raspberry Pi 5. Para além do suporte de hardware, existe uma grande variedade de poderosas bibliotecas de aprendizagem automática que podem ser usadas com o Raspberry Pi, incluindo scikitlearn e LiteRT. Python inclui várias bibliotecas de suporte poderosas, como Matplotlib e plotly para plotamento, NumPy para fornecer operações rápidas em arrays, e Pandas para análise e manipulação de dados. As secções seguintes fornecem exemplos de algumas destas bibliotecas em ação.
15.2 SciKit Learn
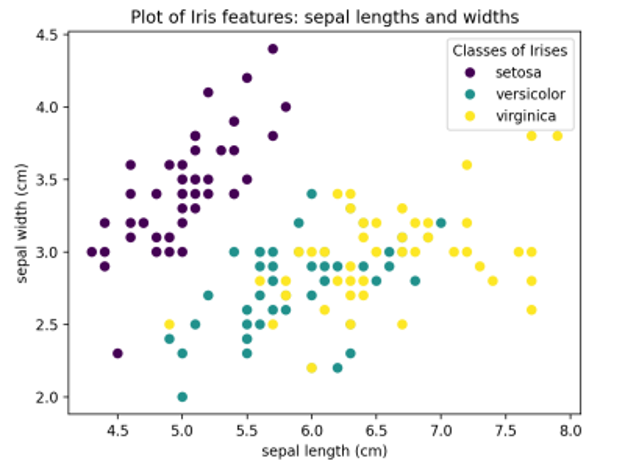
SciKit Learn é uma biblioteca de aprendizagem automática open source que funciona com Python. O SciKit Learn oferece muitas funcionalidades diferentes, incluindo algoritmos de regressão e agrupamento, Análise de Componentes Principais (PCA), Análise Discriminante Linear (LDA) e Máquinas de Vetores de Suporte (SVMs). Todas as formas de aprendizagem automática requerem um conjunto de dados utilizado para treino. O SciKit inclui uma seleção de conjuntos de dados de brinquedos que podem ser usados para experimentar as bibliotecas de aprendizagem automática. As secções seguintes demonstram PCA e SVMs usando o clássico conjunto de dados de flores de íris, que faz parte da coleção de conjuntos de dados de brinquedos. Este conjunto de dados de íris foi originalmente compilado pelo biólogo Ronald Fisher num artigo conhecido de 1936. Este conjunto de dados compreende amostras de três espécies da flor da íris (Iris setosa, Iris virginica e Iris versicolor) e medições do comprimento e da largura tanto dos sépalas1 como das pétalas. A biblioteca SciKit Learn inclui este conjunto de dados de íris para fins de teste e demonstração. O código Python seguinte utiliza o Matplotlib para representar a largura da sépala em função do comprimento da sépala para cada uma das três classes de íris do conjunto de dados.
Dos conjuntos de dados de importação sklearn
importar matplotlib.pyplot como plt
# Carregar o conjunto de dados clássico da íris
íris = conjuntos de dados.load_iris()
# Plotar comprimentos de sépalas vs. larguras para íris no conjunto de dados
fig, ax = plt.Subenredos()
dispersar = machado.Scatter (íris.data[:, 0], íris.data[:, 1], c=íris.alvo)
Axe.set_title("Gráfico das características da íris: comprimentos e larguras de sépalas")
Axe.set(xlabel=íris.feature_names[0], ylabel=íris.feature_names[1])
fig = machado.Lenda (dispersão.legend_elements()[0], íris.target_names, loc="best
", título="Classes de Íris")
Plt.Show()
Executar este código resulta no seguinte gráfico do conjunto de dados de íris:
15.3 Classificação de Imagens SVM
O exemplo seguinte é inspirado no exemplo do SciKit sobre o reconhecimento de dígitos manuscritos e utiliza o conjunto de dados de dígitos manuscritos do repositório de aprendizagem automática da UC Irvine. Este conjunto de dados tem 1797 amostras de imagem compostas por um array de 8x8 píxeis com 10 classes, onde cada classe se refere a um dígito (09). Um curto programa em Python para carregar o conjunto de dados de dígitos manuscritos e exibi-los é mostrado abaixo:
importar matplotlib.pyplot como plt
A partir de dados de importação SkLearn, métricas, SVM
Do sklearn.model_selection importação train_test_split
# carregar conjunto de dados de dígitos escritos à mão
dígitos = conjuntos de dados.load_digits()
# mostrar uma amostra de dez dígitos manuscritos no conjunto de dados
fig, eixos = plt.Subenredos (nrows=2, ncols=5)
Para Ax, digito em Zip(Axes.achatar (), dígitos.Imagens):
Axe.set_axis_off()
Axe.imshow(digit,cmap='gray')
fig.tight_layout()
Plt.Show()
O gráfico que mostra dez dígitos manuscritos no conjunto de dados é mostrado abaixo.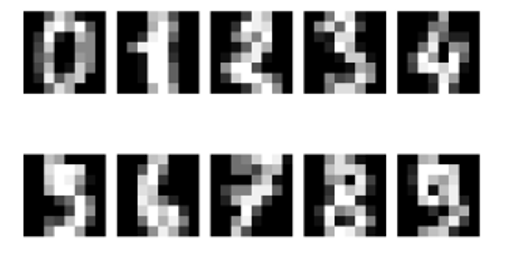
Podemos dividir o conjunto de dados de dígitos manuscritos em dois conjuntos: um conjunto de treino e um conjunto para testes. O SciKit tem uma função para pegar no conjunto de dados de dígitos maiores e dividi-lo ao meio em conjuntos de treino e teste da seguinte forma:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0,5)
onde X é um array das características e y é um vetor de etiquetas que classificam os dados. Assim, podemos treinar um SVM usando metade do conjunto de dados para treino e depois usar a metade restante para testes. A precisão da SVM pode ser determinada comparando os dígitos previstos pela SVM com as etiquetas reais dos dígitos manuscritos e a taxa de reconhecimento pode ser reportada. A taxa de reconhecimento é o número total de imagens de dígitos corretamente identificadas dividido pelo número total de imagens de teste. O código seguinte define um classificador SVM com base em metade do conjunto de dados e depois determina a taxa de reconhecimento usando a outra metade do conjunto de dados como imagens de teste.
importar matplotlib.pyplot como plt
A partir de dados de importação SkLearn, métricas, SVM
Do sklearn.model_selection importação train_test_split
# Lê dígitos e remodela os dígitos como um vetor de imagens
dígitos = conjuntos de dados.load_digits()
n_samples = len(dígitos).imagens)
dados = dígitos.imagens.reformulação((n_samples, -1))
# Criar um classificador de máquina de vetores de suporte
SVM = SVM.SVC()
# Dividir o conjunto de dados: metade para treino e metade para testes
X_train, X_test, y_train, y_test = train_test_split(
dados, dígitos.alvo, test_size=0,5, baralhar=Falso)
# Treina com dígitos manuscritos no conjunto de treino
SVM.Ajuste(X_train, y_train)
# Prever o valor do dígito usando o conjunto de teste
previsto = SVM.Prever(X_test)
# calcular a taxa de reconhecimento
Jogos = 0
para x no intervalo (len(y_test)):
se y_test[x] == previsto[x]:
Jogos += 1
recognition_rate = (matches/len(y_test)) * 100;
print(f'Taxa de reconhecimento: {recognition_rate:.2f}%')
A saída deste código mostra o seguinte:
Taxa de reconhecimento: 96,11%
Isto indica uma taxa de reconhecimento respeitável usando uma SVM para classificação de dígitos manuscritos. Para mais detalhes, podemos traçar uma matriz de confusão para visualizar a precisão de um algoritmo de aprendizagem automática. A matriz de confusão está organizada em linhas e colunas: cada linha representa cada uma das classes de um conjunto de dados e cada coluna representa as previsões feitas. Idealmente, as classes reais e as previsões alinham-se perfeitamente de modo que a diagonal da matriz de confusão seja preenchida com 100 e com 0s em todo o resto. O mártix diagonal corresponde às taxas de reconhecimento verdadeiras, enquanto todas as outras células representam a ocorrência de classificações falsas.
Last modified: Thursday, 18 June 2026, 4:59 AM